









Article
Mémoire d'agent IA : entraîner un agent qui apprend entre les sessions

Qu'est-ce qu'un agent IA ? Dans ma propre pratique, un agent IA est un programme qui ne se contente pas de répondre aux questions, il agit. Il récupère des données selon une planification, analyse ce qu'il trouve, propose l'étape suivante et vérifie sa propre sortie face à un standard avant d'envoyer quoi que ce soit. C'est ce qui distingue un agent d'un chatbot. La question plus difficile, et le sujet de cet article, est la mémoire d'agent IA : si l'agent peut transporter ce qu'il a appris dans une session vers la suivante, ou s'il repart de zéro à chaque fois.
L'objectif que je me suis fixé
Je voulais construire un agent qui ne se contente pas d'assister. Un agent qui agit.
L'idée était simple : configurer des automatisations pour récupérer des données, laisser l'agent analyser ce qu'il trouve, lui faire proposer les prochaines étapes, envoyer ces propositions quelque part pour révision, et à travers cette boucle de feedback — s'améliorer progressivement. À un certain stade, une fois que ses propositions correspondraient systématiquement à ce que je considère comme de bonnes décisions, il arrêterait d'attendre une approbation et commencerait à exécuter de manière autonome.
Pas un chatbot. Pas un copilote. Un système autonome qui gagne son autorité par sa précision démontrée.
C'était l'objectif. J'en ai décrit une partie dans mon article précédent sur les modèles IA locaux. Ceci est le chapitre suivant.
CE QUE J'AI CONSTRUIT — ET CE QU'IL NE POUVAIT PAS FAIRE
La première version était simple par choix. Mais le plus intéressant n'était pas ce qu'elle faisait. Le plus intéressant, c'était ce qu'elle ne pouvait pas faire.
L'agent tourne selon un calendrier, récupère des données, les analyse, et envoie un rapport dans Slack. Pour m'assurer que la sortie soit cohérente, j'ai créé un schéma — un format approuvé contre lequel l'agent se vérifie avant d'envoyer quoi que ce soit. Si quelque chose ne correspond pas, il se corrige. Il boucle jusqu'à ce que la sortie passe. Si quelque chose l'empêche de terminer le processus — comme un appel LLM échoué — il n'envoie pas une sortie dégradée. Il envoie une alerte dans Slack à la place.
J'ai aussi ajouté des exemples positifs. Des sorties approuvées des exécutions précédentes que l'agent peut utiliser comme référence pour produire la suivante.
Ça semblait être un système solide. Et pendant un moment, je le pensais.
CE QUI CONTINUAIT À ME DÉRANGER
Chaque session repart de zéro.
Le schéma est là. Les exemples sont là. Mais l'agent ne sait pas avec quoi il a galéré hier. Il ne sait pas quelle règle il continue de violer. Il ne sait pas ce qu'il a déjà compris.
Et ça change tout.
La boucle d'autocorrection fonctionne au sein d'une seule session. Entre les sessions, rien ne s'accumule. Donc l'incohérence que j'observais n'était pas un problème de configuration. Ce n'était pas un problème de prompting.
Le problème n'était pas technique. Il était structurel.
AUTOCORRECTION VS AUTO-AMÉLIORATION
C'est là que j'ai réalisé quelque chose d'important.
L'autocorrection signifie que l'agent détecte ses propres erreurs avant d'envoyer la sortie. Ça se passe au sein d'une seule exécution, contre un schéma fixe. La session se termine, et tout ce que l'agent a appris — disparaît.
L'auto-amélioration signifie que l'agent construit quelque chose d'une exécution à l'autre. Chaque session laisse une trace que la suivante peut utiliser. Les erreurs deviennent des règles. Les règles deviennent du contexte. Le contexte façonne la prochaine sortie avant même que la génération ne commence.
Le premier est un filtre de qualité. Le second est quelque chose qui se rapproche davantage de l'apprentissage.
Et cette distinction ne concerne pas seulement les agents IA. C'est la différence entre les systèmes qui répètent et ceux qui évoluent. Entre les gens qui corrigent leurs erreurs et ceux qui cessent de faire les mêmes. La plupart des organisations ont de l'autocorrection. Très peu ont une véritable auto-amélioration. Le mécanisme semble similaire vu de l'extérieur. L'architecture en dessous est complètement différente.
Ce que j'avais, c'était un bon filtre de qualité. Ce qui me manquait, c'était la couche d'accumulation en dessous.
COMMENT DONNER UNE MÉMOIRE À UN AGENT IA
C'est une question légitime — et une que j'ai dû résoudre moi-même.
Claude Code a un fichier appelé CLAUDE.md. Il se charge automatiquement au début de chaque session. Quand on dit à l'agent de se souvenir de quelque chose pour les prochaines exécutions, il peut l'écrire dedans. Et la prochaine fois, ce sera là. C'est de la vraie persistance. Ce n'est pas une illusion.
Donc quand Claude Code confirme qu'il se souviendra de quelque chose — il ne ment pas.
Le problème, c'est ce que « là » signifie réellement en pratique.
Rejoindre la Bibliothèque
Accès complet à mes observations, histoires personnelles et ce que j'entends des gens que je rencontre.
Rejoindre la Bibliothèque · €29,99 par anRecevez l’article complet par e-mail et n’hésitez pas à répondre si vous souhaitez en discuter davantage.
Résumé
Questions fréquentes sur le sujet de l'article
Qu'est-ce qu'un agent IA ?
L'IA peut-elle avoir une mémoire ?
Les agents IA peuvent-ils apprendre dans le temps ?
Quelle est la différence entre l'autocorrection et l'auto-amélioration d'un agent IA ?
Qu'est-ce que CLAUDE.md et quelles sont ses limites pour les agents IA ?
Pourquoi chaque session d'agent IA repart-elle de zéro ?
Qu'est-ce qu'une couche de mémoire structurée pour les agents IA ?
Peut-on faire tourner des agents IA autonomes en local ?
Que faut-il pour construire un agent IA qui gagne son autonomie ?
Si vous avez des pensées, des questions ou des retours, n’hésitez pas à m’écrire à mail@richardgolian.com.
 LinkedIn
LinkedIn




Articles connexes
L'IA crée le visuel, la newsletter et la page produit plus vite qu'une personne. À celui qui le faisait auparavant, il ne reste qu'une chose — le jugement, savoir si le résultat est bon. Mais la plupart des gens ont un moins bon jugement que l'IA. Et celui qui ne sait pas juger la qualité ne sait pas non plus déléguer. Comment savoir si le vôtre est le jugement sur lequel une entreprise s'appuie, ou celui qu'elle peut remplacer ?
En avril, dans la première partie de cette série, j'écrivais sur un système d'IA prédictif commencé sur mon propre ordinateur. Le logiciel avait alors quelques heures, le registre de prédictions était vide. Depuis, les enregistrements ont révélé une chose qui, avec le recul, était prévisible — le système ne comprend pas encore le marché qu'on lui demande de prévoir. Il sait trouver le contexte macro, la valeur comptable des entreprises, les bénéfices. Mais il ne sait pas assembler ces choses en quelque chose qui l'aide à comprendre le prix.
Je construis un système d'IA pour prédire le S&P 500. Il tourne sur ma propre machine, utilise des données publiques gratuites — yfinance, FRED, le jeu de données Shiller — et évalue chaque prévision face à la réalité. Cette série documente la construction elle-même : les décisions, la méthodologie, les erreurs. Ce que je partagerai finalement du système en fonctionnement est une question séparée, et honnête.
Plus d'articles
La même tâche, deux modèles. Fable 5 contre Opus 4.8. Sur le papier, Fable est le meilleur modèle, avec un contexte plus large et de meilleures caractéristiques. Et pourtant il a perdu. Opus a traité la tâche en un seul tour de contrôle pour 721 000 tokens, tandis que Fable en a exigé neuf et a brûlé 2,78 millions de tokens. La différence ne tenait pas au modèle, mais à la façon dont j'ai formulé la tâche. Et je le sais, parce que je l'ai mesuré.
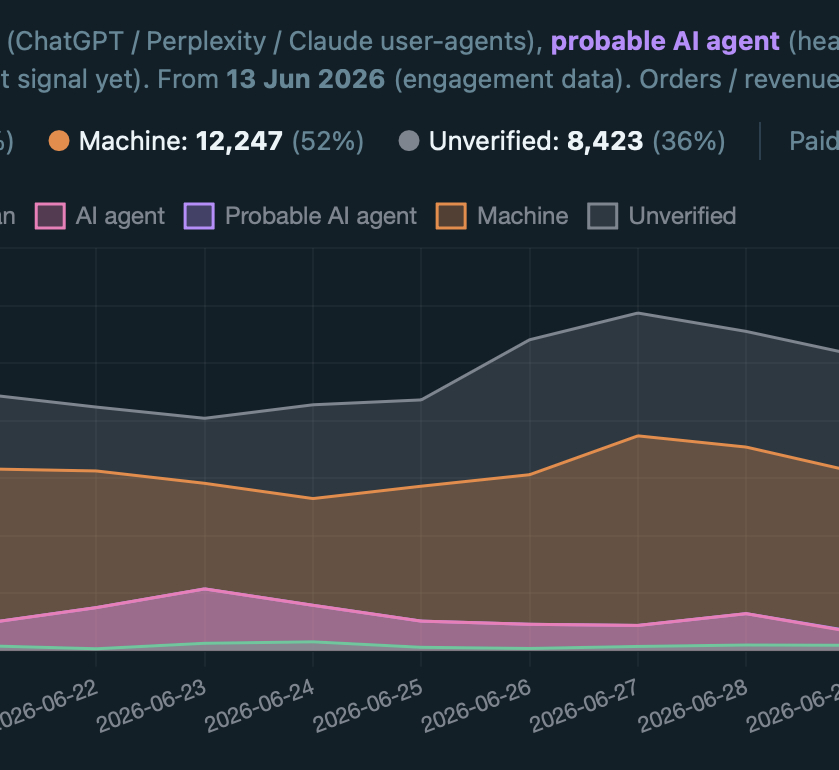
J'ai écrit autrefois sur la construction de mon propre outil d'analytics respectueux de la vie privée. Il détectait les bots dès la première version, mais cela n'a pas suffi. Les visites directes pesaient étrangement lourd. Quand quelqu'un affirme que 20 % de ses visites sont des bots et 80 % des humains, je le pensais aussi autrefois. Aujourd'hui, je dirais que la proportion inverse est plus proche de la vérité. Voici comment j'en suis arrivé là.

J'ai Heidegger et mon carnet à côté de moi. Je me demande où tout cela nous mène, où l'intelligence artificielle nous emporte.
Soixante-dix pour cent. C'est là que commence le premier résultat de l'IA, même lorsque vous lui donnez tout le contexte de l'entreprise et les meilleurs exemples du passé. Nous parlons du type de résultat qui ne peut pas se définir de façon programmatique. Il est plus complexe. Souvent, il s'agit d'un travail créatif. Sur un type de résultat répété, j'ai atteint quatre-vingts pour cent en une semaine. Chaque point de pourcentage supplémentaire est plus difficile que le précédent.
Pendant longtemps, nous avons pris internet pour la route principale. Le lieu où se déroulent le travail et les relations. Pourtant, la plupart de ce que nous y voyons aujourd'hui est, ou sera bientôt, généré par IA : texte, images, profils et commentaires. Internet se transforme en un jeu en ligne rempli de bots, où vous ne pouvez être sûr qu'un être humain se trouve de l'autre côté de quoi que ce soit. Alors je me demande : le monde en ligne était-il la route principale, ou seulement un détour temporaire dont une partie des gens reviendra, de retour hors ligne ?
Il y a quelques jours, j'ai fait passer un entretien à un responsable marketing senior. Un homme d'expérience, des années de pratique. Je l'ai interrogé sur l'IA. Il m'a dit qu'il ne l'utilise presque pas. Il a eu une mauvaise expérience avec un résultat et a conclu qu'il était trop expérimenté pour que cela lui apporte quelque chose tant que ce n'est pas parfait. Je connais aussi l'autre versant — des professionnels qui automatisent tout ce qui peut l'être.
L'Europe n'a pas les capacités pour faire face à une guerre de drones massive et à grande échelle comme celle que nous voyons en Ukraine. Trois dépendances l'affaiblissent : la Chine fournit le matériau physique des systèmes de défense, les États-Unis fournissent les capacités que l'Europe n'a pas, et vingt-sept États ne parviennent pas à s'entendre sur le rythme, ni sur qui paie. Des plans de réarmement existent, mais ils sont mis en œuvre lentement.

Quatre jours en Catalogne. Sans ordinateur, sans IA, presque sans réseaux sociaux. J'ai acheté ce carnet pour y noter ce à quoi je penserais et ce que je rencontrerais et apprendrais durant le voyage.