









Article
Quand votre agent IA rejoint l'équipe

De l'apprentissage au contrôle d'accès
Dans mon article précédent, j'ai décrit la construction d'un agent IA qui apprend entre les sessions. Un agent doté d'une mémoire structurée, d'une boucle d'autocorrection et d'un système d'accumulation d'expérience d'une exécution à l'autre.
Dès que d'autres personnes ont eu besoin d'y accéder, le problème a complètement changé. Il ne s'agissait plus de savoir si l'agent pouvait apprendre. Il s'agissait de savoir qui avait le droit de lui enseigner.
Que se passe-t-il quand votre équipe accède à un agent IA
La plupart des articles sur les agents IA se concentrent sur ce que l'agent peut faire. Très peu parlent de ce qui se passe quand quelqu'un d'autre que son créateur commence à l'utiliser.
J'ai construit un bot Slack. L'idée était simple : donner à l'équipe un moyen d'interagir directement avec l'agent — poser des questions, demander des analyses, obtenir des rapports. Pas de terminal. Pas de code. Juste Slack.
Ça a fonctionné immédiatement. Et c'est là que le vrai problème est apparu.
Le chat libre avec un agent IA est une interface puissante. C'est aussi un risque. Si n'importe qui dans l'équipe peut écrire n'importe quoi à l'agent, n'importe qui peut accidentellement écraser sa mémoire, modifier son comportement ou déclencher des actions non prévues. L'agent ne juge pas l'autorité. Il traite les entrées.
La question n'était pas de savoir si l'équipe devait avoir accès. La question était : quel type d'accès ?
Contrôle d'accès basé sur les rôles pour les agents IA
J'ai fini par mettre en place un système de rôles. Trois niveaux : administrateur, analyste, observateur.
L'observateur peut lire les rapports et voir ce que l'agent produit. Rien de plus. Pas de commandes, pas de chat, aucune influence sur le comportement.
L'analyste peut faire davantage. Il peut poser des questions. Il peut exécuter des commandes prédéfinies. Et — c'est le point important — il peut écrire dans la mémoire de l'agent. Mais uniquement via une commande explicite, pas par une conversation libre. Si un analyste tape une instruction de mémorisation dans le bon format, l'agent l'enregistre. S'il essaie de l'écrire comme un message informel, le système l'ignore.
L'administrateur a un accès illimité. Chat libre, commandes directes, écritures en mémoire, modifications de configuration.
Cela ressemble à un modèle de permissions classique. Mais la distinction qui compte n'est pas qui peut lire ou écrire. C'est qui peut enseigner. Parce que chaque entrée en mémoire change ce que l'agent sait. Et ce que l'agent sait façonne chaque production future.
Pourquoi la mémoire d'un agent IA devient une base de connaissances partagée
C'est quelque chose que je n'ai pleinement compris qu'en le voyant en pratique.
Dans l'article précédent, j'ai décrit la couche de mémoire structurée — un fichier que l'agent lit avant chaque exécution, contenant les leçons des sessions passées. Ce que je n'avais pas dit, c'est ce qui se passe quand cette mémoire devient partagée.
Dès que plusieurs personnes contribuent à la mémoire de l'agent, il cesse d'être un outil personnel. Il devient une base de connaissances partagée. Chaque entrée affecte chaque session future — pas seulement pour la personne qui l'a écrite, mais pour tous ceux qui interagissent avec l'agent.
Un accès non contrôlé à cette mémoire est un vrai risque. Non pas parce que les gens ont de mauvaises intentions. Mais parce que l'agent ne fait pas la différence entre un insight méthodologique mûrement réfléchi et une remarque désinvolte tapée sans réfléchir. Il traite les deux comme des vérités équivalentes.
L'accès à la mémoire uniquement par commande pour les analystes était le compromis. On peut contribuer. Mais on le fait délibérément, dans un format structuré, et c'est consigné.
Que se passe-t-il quand l'agent se trompe de méthodologie
Celle-là, je ne l'avais pas vue venir.
Rejoindre la Bibliothèque
Accès complet à mes observations, histoires personnelles et ce que j'entends des gens que je rencontre.
Rejoindre la Bibliothèque · €29,99 par anRecevez l’article complet par e-mail et n’hésitez pas à répondre si vous souhaitez en discuter davantage.
Résumé
Questions fréquentes sur le sujet de l'article
Qu'est-ce que le contrôle d'accès basé sur les rôles pour les agents IA ?
Pourquoi la mémoire d'un agent IA est-elle un risque quand elle est partagée au sein d'une équipe ?
Les agents IA peuvent-ils se retrouver piégés dans des erreurs logiques ?
Quelle est la différence entre un agent IA qui se corrige et un agent qui apprend vraiment ?
Comment déployer un agent IA pour une équipe en toute sécurité ?
Quel est le plus grand défi quand on fait évoluer un agent IA d'un usage solo à un usage en équipe ?
Si vous avez des pensées, des questions ou des retours, n’hésitez pas à m’écrire à mail@richardgolian.com.
 LinkedIn
LinkedIn




Articles connexes
L'IA crée le visuel, la newsletter et la page produit plus vite qu'une personne. À celui qui le faisait auparavant, il ne reste qu'une chose — le jugement, savoir si le résultat est bon. Mais la plupart des gens ont un moins bon jugement que l'IA. Et celui qui ne sait pas juger la qualité ne sait pas non plus déléguer. Comment savoir si le vôtre est le jugement sur lequel une entreprise s'appuie, ou celui qu'elle peut remplacer ?
En avril, dans la première partie de cette série, j'écrivais sur un système d'IA prédictif commencé sur mon propre ordinateur. Le logiciel avait alors quelques heures, le registre de prédictions était vide. Depuis, les enregistrements ont révélé une chose qui, avec le recul, était prévisible — le système ne comprend pas encore le marché qu'on lui demande de prévoir. Il sait trouver le contexte macro, la valeur comptable des entreprises, les bénéfices. Mais il ne sait pas assembler ces choses en quelque chose qui l'aide à comprendre le prix.
Je construis un système d'IA pour prédire le S&P 500. Il tourne sur ma propre machine, utilise des données publiques gratuites — yfinance, FRED, le jeu de données Shiller — et évalue chaque prévision face à la réalité. Cette série documente la construction elle-même : les décisions, la méthodologie, les erreurs. Ce que je partagerai finalement du système en fonctionnement est une question séparée, et honnête.
Plus d'articles
La même tâche, deux modèles. Fable 5 contre Opus 4.8. Sur le papier, Fable est le meilleur modèle, avec un contexte plus large et de meilleures caractéristiques. Et pourtant il a perdu. Opus a traité la tâche en un seul tour de contrôle pour 721 000 tokens, tandis que Fable en a exigé neuf et a brûlé 2,78 millions de tokens. La différence ne tenait pas au modèle, mais à la façon dont j'ai formulé la tâche. Et je le sais, parce que je l'ai mesuré.
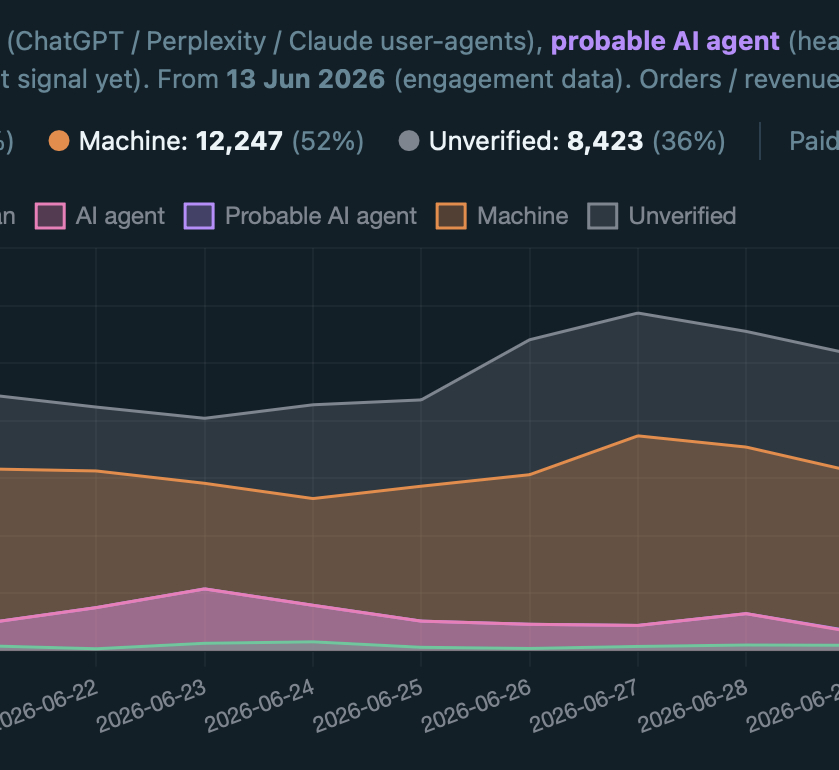
J'ai écrit autrefois sur la construction de mon propre outil d'analytics respectueux de la vie privée. Il détectait les bots dès la première version, mais cela n'a pas suffi. Les visites directes pesaient étrangement lourd. Quand quelqu'un affirme que 20 % de ses visites sont des bots et 80 % des humains, je le pensais aussi autrefois. Aujourd'hui, je dirais que la proportion inverse est plus proche de la vérité. Voici comment j'en suis arrivé là.

J'ai Heidegger et mon carnet à côté de moi. Je me demande où tout cela nous mène, où l'intelligence artificielle nous emporte.
Soixante-dix pour cent. C'est là que commence le premier résultat de l'IA, même lorsque vous lui donnez tout le contexte de l'entreprise et les meilleurs exemples du passé. Nous parlons du type de résultat qui ne peut pas se définir de façon programmatique. Il est plus complexe. Souvent, il s'agit d'un travail créatif. Sur un type de résultat répété, j'ai atteint quatre-vingts pour cent en une semaine. Chaque point de pourcentage supplémentaire est plus difficile que le précédent.
Pendant longtemps, nous avons pris internet pour la route principale. Le lieu où se déroulent le travail et les relations. Pourtant, la plupart de ce que nous y voyons aujourd'hui est, ou sera bientôt, généré par IA : texte, images, profils et commentaires. Internet se transforme en un jeu en ligne rempli de bots, où vous ne pouvez être sûr qu'un être humain se trouve de l'autre côté de quoi que ce soit. Alors je me demande : le monde en ligne était-il la route principale, ou seulement un détour temporaire dont une partie des gens reviendra, de retour hors ligne ?
Il y a quelques jours, j'ai fait passer un entretien à un responsable marketing senior. Un homme d'expérience, des années de pratique. Je l'ai interrogé sur l'IA. Il m'a dit qu'il ne l'utilise presque pas. Il a eu une mauvaise expérience avec un résultat et a conclu qu'il était trop expérimenté pour que cela lui apporte quelque chose tant que ce n'est pas parfait. Je connais aussi l'autre versant — des professionnels qui automatisent tout ce qui peut l'être.
L'Europe n'a pas les capacités pour faire face à une guerre de drones massive et à grande échelle comme celle que nous voyons en Ukraine. Trois dépendances l'affaiblissent : la Chine fournit le matériau physique des systèmes de défense, les États-Unis fournissent les capacités que l'Europe n'a pas, et vingt-sept États ne parviennent pas à s'entendre sur le rythme, ni sur qui paie. Des plans de réarmement existent, mais ils sont mis en œuvre lentement.

Quatre jours en Catalogne. Sans ordinateur, sans IA, presque sans réseaux sociaux. J'ai acheté ce carnet pour y noter ce à quoi je penserais et ce que je rencontrerais et apprendrais durant le voyage.