







Artículo
Construyendo un sistema de IA que predice la bolsa y se evalúa a sí mismo

En julio de 2024 escribí sobre los cambios de ánimo del mercado bursátil. Describí el seguimiento de las ratios de valoración junto con las narrativas mediáticas como un termómetro de ánimo. Aquel artículo terminaba con una frase a la que vuelvo a menudo: el mercado bursátil es un reflejo de las emociones y comportamientos humanos colectivos.
Dos años después, ese termómetro sigue viviendo en una hoja de cálculo de Google: ratios de valoración en columnas, mis propios comentarios sobre lo que decía la prensa financiera al lado. Funciona para mí. No funciona para nadie más. Y, lo que es más importante, no se puede comprobar. No puedo señalar un registro calibrado de cuántas veces mis lecturas fueron acertadas, cuántas estuvieron equivocadas, ni si soy mejor que lanzar una moneda al aire cuando afirmo ver una valoración elevada.
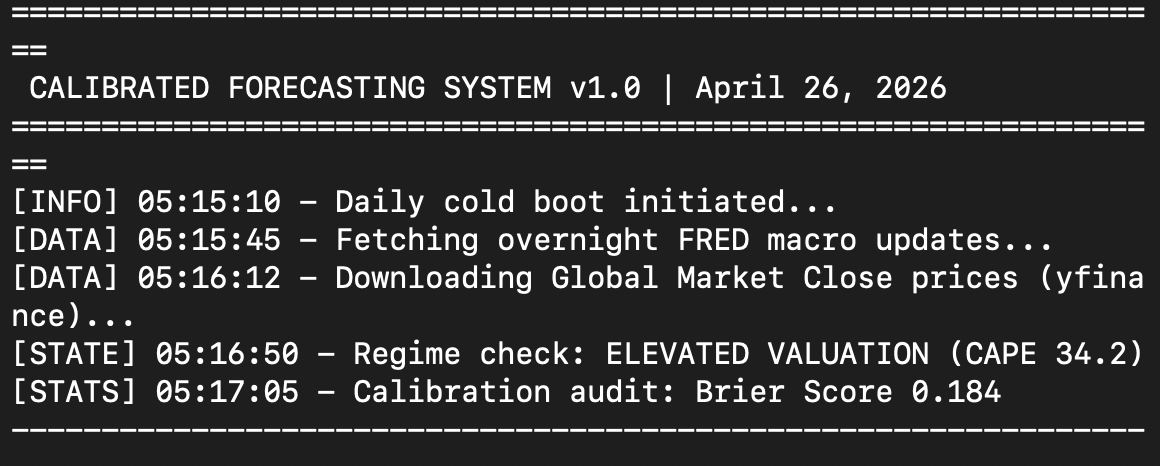
Así que decidí construir algo. Llevo trabajando en ello desde las cinco de la mañana. Estoy escribiendo esto a las ocho. La primera versión ya corre en mi propia máquina. El pipeline funciona de principio a fin. Aún no tiene suficientes predicciones evaluadas dentro como para decirme algo significativo. Esa parte está justo empezando. Este artículo es el primero de una serie que documenta la construcción en sí, y lo que el sistema me dice una vez que el registro empiece a llenarse.
¿SOBRE QUÉ SE CONSTRUYE UN SISTEMA DE PREDICCIÓN CALIBRADO?
Tres artículos anteriores convergen en el diseño de lo que he construido. Cada uno es una idea separada. Juntos forman la columna vertebral.
El primero es la asimetría riesgo-recompensa. Cada predicción que el sistema emite viene con probabilidades explícitas y un número de confianza. Tiene que responder a la pregunta que me sigo haciendo a mí mismo en voz alta. Si me equivoco, ¿cuánto pierdo? Si acierto, ¿cuánto gano? ¿Y está esa proporción a mi favor?
El segundo es la calidad de la decisión por encima del resultado de la decisión. Atraviesa tanto La toma de decisiones en marketing y publicidad bajo incertidumbre como Cometo error tras error. La métrica principal no es la tasa de acierto. Es el error de calibración. Cuando el sistema dice 70 por ciento, ¿el mundo entrega 70 por ciento? Un predictor que dice 95 por ciento y acierta el 80 por ciento de las veces es más peligroso que uno que dice 70 por ciento y acierta el 70 por ciento de las veces. La construcción impone esto en su propia interfaz. La tasa de acierto nunca se reporta sin el error de calibración al lado. Los números solo cobrarán sentido cuando el registro tenga suficientes predicciones evaluadas. Un artículo posterior de esta serie entrará en cómo se calcula la comparación.
El tercero es el termómetro de ánimo. Lo describí como mi forma de leer el mercado, en parte a través de lo caro que estaba frente a su propia historia, y en parte a través de cómo hablaba de él la prensa financiera. Volví a las dos mitades más adelante, en El mercado bursátil zumba de esperanza y ¿Sabes qué es el CAPE?. En la primera fase de la construcción, el sistema formaliza solo la mitad de la valoración. Calcula el percentil CAPE frente a la distribución completa desde 1871. Clasifica el mercado en uno de dieciocho regímenes. Cada predicción inteligente se condiciona al régimen en el que se hizo. La mitad narrativa se queda en la hoja de cálculo, por ahora.
¿QUÉ HACE REALMENTE LA PRIMERA VERSIÓN?
A diario, en mi propia máquina, la construcción ingiere datos OHLCV del S&P 500, indicadores macro de FRED y la serie CAPE de Shiller. También extrae fundamentales de valoración de yfinance.
Después calcula características de valoración. P/E pasado y proyectado. Precio sobre valor en libros. Rentabilidad por dividendo. Percentil CAPE frente a la larga distribución histórica. A partir de esas características etiqueta el régimen de hoy, eligiendo uno de dieciocho. Cinco ejemplos: tendencia alcista de baja volatilidad, corrección de alta volatilidad, lateral, valoración elevada o suelo cíclico.
Después emite predicciones para el S&P 500 a través de seis horizontes, desde un día hasta doce meses. Cada predicción es una distribución de probabilidad con un número de confianza calibrado adjunto. No es un solo número.
Cada predicción se evalúa en su fecha de revisión. El registro nunca se edita. El sistema se juzga a sí mismo por agregados, no por aciertos individuales. Se requiere una muestra mínima de treinta predicciones por métrica antes de que cualquier número se considere significativo. El registro empezó hoy. La parte interesante de esta serie comienza una vez que deje de ser pequeño.
Únete a la Biblioteca
Acceso completo a mis pensamientos, historias personales, hallazgos y lo que me cuentan las personas con las que me encuentro.
Únete a la Biblioteca · €29,99 al añoReciba el artículo completo por correo electrónico y no dude en responder si desea seguir comentándolo.
Aviso legal
Fuentes
Resumen
Preguntas frecuentes sobre el tema del artículo
¿Puede la IA predecir el mercado bursátil?
¿Qué significa calibrar un sistema de predicción?
¿Por qué la tasa de acierto es una métrica engañosa para los pronósticos bursátiles?
¿Qué es el ratio CAPE y por qué importa para predecir el S&P 500?
¿Puede un sistema de pronóstico bursátil correr localmente sin servicios en la nube?
¿Cómo mantienes honesto un registro de pronósticos?
Si tienes pensamientos, preguntas o comentarios, no dudes en escribirme a mail@richardgolian.com.
 LinkedIn
LinkedIn




Artículos relacionados
En abril, en la primera parte de esta serie, escribí sobre un sistema predictivo de IA que empecé a desarrollar en mi propio ordenador. Entonces el software tenía unas pocas horas y el registro de predicciones estaba vacío. Desde entonces, los registros del sistema mostraron una cosa: el sistema todavía no entiende el mercado que se le pide predecir. Sabe encontrar el contexto macro, el valor contable de las empresas, las ganancias. Pero no sabe juntar esas cosas en algo que le ayude a entender el precio.
La IA crea el gráfico, el newsletter y la página de producto más rápido que una persona. A quien antes lo hacía le queda una sola cosa: el criterio, saber si el resultado es bueno. Pero la mayoría tiene peor criterio que la IA. Y quien no sabe juzgar la calidad tampoco sabe delegar. ¿Cómo saber si el tuyo es el criterio en el que una empresa se apoya, o el que puede reemplazar?
Antes de enseñarle algo a la IA, necesitas ver lo que te está ocultando.
Más artículos
Tengo a Heidegger y mi cuaderno al lado. Me pregunto hacia dónde se dirige todo esto, hacia dónde nos lleva la inteligencia artificial.
Setenta por ciento. Ahí empieza el primer resultado de la IA, incluso cuando le das todo el contexto de la empresa y los mejores ejemplos del pasado. Hablamos del tipo de resultado que no se puede definir de forma programática. Es más complejo. A menudo se trata de trabajo creativo. Con un tipo de resultado repetido llegué al ochenta por ciento en una semana. Cada punto porcentual adicional es más difícil que el anterior.
Durante mucho tiempo tratamos internet como el camino principal. El lugar donde ocurren el trabajo y las relaciones. Pero la mayoría de lo que vemos en él hoy ya es, o pronto será, generado por IA: texto, imágenes, perfiles y comentarios. Internet se está convirtiendo en un juego online lleno de bots, donde no puedes estar seguro de que al otro lado haya una persona. Así que me pregunto: ¿fue el mundo online el camino principal, o solo un desvío temporal del que parte de la gente regresará, de vuelta al offline?
Hace unos días entrevisté a un sénior del marketing. Un hombre con experiencia, años de práctica. Le pregunté por la IA. Me dijo que apenas la usa. Tuvo una mala experiencia con un resultado y decidió que era demasiado sénior para que le aportara algo cuando no es perfecta. Conozco también la otra cara: profesionales que automatizan todo lo que se puede automatizar.
Europa no tiene capacidad para hacer frente a una guerra de drones masiva y a gran escala como la que vemos en Ucrania. La debilitan tres dependencias: China suministra el material físico de los sistemas de defensa, Estados Unidos aporta las capacidades que Europa no tiene, y veintisiete Estados no logran ponerse de acuerdo sobre con qué rapidez, ni quién paga. Existen planes de rearme, pero se ejecutan con lentitud.
Praga, 13 de mayo de 2026. De camino al trabajo empecé a pensar en algo que se me quedó dentro durante días. Si en los próximos diez años desaparece la mayor parte del trabajo rutinario delante de un ordenador, y con ella desaparece buena parte del trabajo manual repetitivo, ¿qué pasa con el flujo del dinero? ¿Quién paga a quién y por qué? ¿Qué capas económicas existirán, qué tamaño tendrán y qué relaciones se establecerán entre ellas? Este es el mapa de seis capas que esbocé como respuesta.
Ayer no podía despegarme del ordenador. Cuando levanté la cabeza, eran las ocho y media de la tarde. Llevaba unas tres horas sentado solo arriba.
¿Me quitará la IA el trabajo? Un formador certificado de Google me dijo en junio de 2024 que mi profesión dejaría de existir. Veintidós meses después, mi cargo no ha cambiado, pero el noventa por ciento de lo que hago durante el día es distinto. He delegado más de mi pensamiento a agentes de IA de lo que jamás creí posible. No tengo miedo. Esto es por qué, y qué significa para cualquiera que se haga la misma pregunta.
Cuatro días en Cataluña. Sin ordenador, sin IA, casi sin redes sociales. Me compré este cuaderno para anotar lo que pensaría y lo que encontraría y aprendería durante el viaje.