








Article
Construire un système d'IA qui prédit la bourse et s'évalue lui-même

En juillet 2024, j'ai écrit sur les changements d'humeur du marché boursier. J'ai décrit le suivi des ratios de valorisation aux côtés des récits médiatiques comme un thermomètre d'humeur. Cet article se terminait par une phrase à laquelle je reviens souvent : le marché boursier est un reflet des émotions et comportements humains collectifs.
La question est : une IA peut-elle m'aider à l'analyser et à le prédire ? Une IA peut-elle prédire la bourse ? Pas avec une précision ponctuelle, et tout système qui prétend le contraire devrait être ignoré. Ce qu'elle peut faire, c'est produire des probabilités calibrées sur le mouvement des prix et le régime de valorisation. Elle vérifie ensuite si ces probabilités tiennent sur des centaines de prévisions. C'est le système que je construis.
Deux ans plus tard, ce thermomètre vit toujours principalement dans une feuille de calcul Google — ratios de valorisation en colonnes, mes propres commentaires sur ce que disait la presse financière à côté. Cela fonctionne pour moi. Cela ne fonctionne pour personne d'autre. Et plus important encore, cela ne peut pas être testé. Je ne peux pas pointer vers un registre calibré du nombre de fois où mes lectures ont été justes, du nombre de fois où elles ont été fausses, ou si je vaux mieux qu'un tirage à pile ou face quand je prétends voir une valorisation élevée.
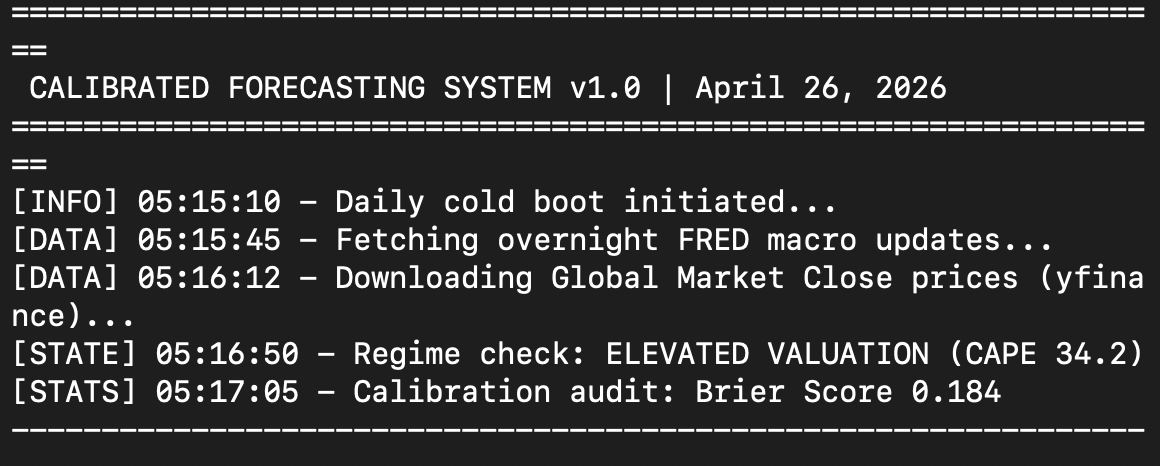
Alors j'ai décidé de construire quelque chose. Je suis dessus depuis cinq heures du matin. Je l'écris à huit heures. La première version tourne désormais sur ma propre machine. Le pipeline fonctionne de bout en bout. Il n'a pas encore assez de prédictions évaluées pour me dire quelque chose de significatif — cette partie ne fait que commencer. Cet article est le premier d'une série qui documente la construction elle-même, et ce que le système me dit une fois que le registre commence à se remplir.
SUR QUOI REPOSE UN SYSTÈME DE PRÉDICTION CALIBRÉ ?
Trois articles plus anciens convergent dans la conception de ce que j'ai construit. Chacun est une idée distincte. Ensemble, ils en forment la colonne vertébrale.
Le premier est l'asymétrie risque-récompense. Chaque prédiction émise par le système s'accompagne de probabilités explicites et d'un nombre de confiance. Elle doit répondre à la question que je continue de me poser à voix haute. Si je me trompe, combien je perds ? Si j'ai raison, combien je gagne ? Et ce ratio est-il en ma faveur ?
Le second est la qualité de la décision plutôt que le résultat de la décision. Cela traverse à la fois La prise de décision en marketing et publicité dans l'incertitude et Je fais erreur sur erreur. La métrique principale n'est pas le taux de réussite. C'est l'erreur de calibration. Quand le système dit 70 pour cent, le monde livre-t-il 70 pour cent ? Un prédicteur qui dit 95 pour cent et a raison 80 pour cent du temps est plus dangereux qu'un prédicteur qui dit 70 pour cent et a raison 70 pour cent du temps. La construction impose cela dans sa propre interface. Le taux de réussite n'est jamais reporté sans l'erreur de calibration à côté. Les chiffres ne deviendront significatifs qu'une fois que le registre aura suffisamment de prédictions évaluées. Un article ultérieur de cette série traitera de la façon dont la comparaison est calculée.
Le troisième est le thermomètre d'humeur. Je l'ai décrit comme ma façon de lire le marché — en partie à travers son coût par rapport à sa propre histoire, et en partie à travers la façon dont la presse financière en parlait. Je suis revenu sur les deux moitiés plus tard, dans Le marché boursier vibre d'espoir et Savez-vous ce qu'est le CAPE ?. Dans la première phase de la construction, le système ne formalise que la moitié valorisation. Il calcule le percentile CAPE par rapport à la distribution complète depuis 1871. Il classe le marché dans l'un des dix-huit régimes. Chaque prédiction intelligente est conditionnée au régime dans lequel elle a été faite. La moitié narrative reste dans la feuille de calcul, pour l'instant.
QUE FAIT RÉELLEMENT LA PREMIÈRE VERSION ?
Quotidiennement, sur ma propre machine, la construction ingère les données OHLCV du S&P 500, les indicateurs macro de FRED, et la série CAPE de Shiller. Elle extrait également les fondamentaux de valorisation depuis yfinance.
Elle calcule ensuite des caractéristiques de valorisation. P/E historique et prévisionnel. Prix sur valeur comptable. Rendement du dividende. Percentile CAPE par rapport à la longue distribution historique. À partir de ces caractéristiques, elle étiquette le régime du jour, en choisissant l'un des dix-huit. Cinq exemples : tendance haussière à faible volatilité, correction à forte volatilité, sans direction, valorisation élevée ou creux cyclique.
Elle émet ensuite des prédictions pour le S&P 500 sur six horizons, d'un jour à douze mois. Chaque prédiction est une distribution de probabilité avec un nombre de confiance calibré attaché. Ce n'est pas un nombre unique.
Chaque prédiction est évaluée à sa date de revue. Le registre n'est jamais édité. Le système se juge lui-même par agrégats, non par succès individuels. Un échantillon minimum de trente prédictions par métrique est requis avant qu'un nombre soit considéré comme significatif. Le registre a commencé aujourd'hui. La partie intéressante de cette série commence une fois qu'il cesse d'être petit.
CE QUE CE SYSTÈME N'EST PAS
Ce ne sont pas des conseils en investissement. Il ne recommande pas d'acheter ou de vendre quoi que ce soit.
Il ne prédit ni les sommets ni les creux avec précision ponctuelle. Il dit « les valorisations sont au 92e percentile par rapport à l'histoire ». Il ne dit pas « le marché atteindra son sommet dans onze jours ».
Il ne prédit pas d'actions individuelles. Comme je l'ai soutenu dans Comment commencer à investir dans un ETF indiciel, les actions individuelles, c'est jouer au football contre Messi pour les investisseurs particuliers. La construction vise le S&P 500, pas Nvidia ni Tesla.
Il n'est pas construit autour d'une narration de prédiction unique. Un système probabiliste se juge par sa calibration sur de nombreuses prédictions, non par le fait qu'une seule d'entre elles se soit avérée juste. Le taux de réussite seul est trompeur. La construction reporte l'erreur de calibration à côté du taux de réussite par conception, jamais séparément.
Il ne tourne pas dans le cloud. Il n'y a pas de couche SaaS, pas d'intégration de courtier, pas de dépendance distante. Le tout tourne localement sur ma propre machine, sans relation commerciale avec quoi que ce soit qu'il prévoit.
Rejoindre la Bibliothèque
Accès complet à mes pensées, histoires personnelles, observations et ce que j'entends des gens que je rencontre.
Rejoindre la Bibliothèque · €29,99 par anRecevez l’article complet par e-mail et n’hésitez pas à répondre si vous souhaitez en discuter davantage.
Avertissement
Sources
Résumé
Questions fréquentes sur le sujet de l'article
Une IA peut-elle prédire le marché boursier ?
Que signifie calibrer un système de prédiction ?
Pourquoi le taux de réussite est-il une métrique trompeuse pour les prévisions boursières ?
Qu'est-ce que le ratio CAPE et pourquoi importe-t-il pour prédire le S&P 500 ?
Un système de prévision boursière peut-il tourner localement sans services cloud ?
Comment garder honnête un registre de prévisions ?
Si vous avez des pensées, des questions ou des retours, n’hésitez pas à m’écrire à mail@richardgolian.com.
 LinkedIn
LinkedIn




Articles connexes
L'IA crée le visuel, la newsletter et la page produit plus vite qu'une personne. À celui qui le faisait auparavant, il ne reste qu'une chose — le jugement, savoir si le résultat est bon. Mais la plupart des gens ont un moins bon jugement que l'IA. Et celui qui ne sait pas juger la qualité ne sait pas non plus déléguer. Comment savoir si le vôtre est le jugement sur lequel une entreprise s'appuie, ou celui qu'elle peut remplacer ?
En avril, dans la première partie de cette série, j'écrivais sur un système d'IA prédictif commencé sur mon propre ordinateur. Le logiciel avait alors quelques heures, le registre de prédictions était vide. Depuis, les enregistrements ont révélé une chose qui, avec le recul, était prévisible — le système ne comprend pas encore le marché qu'on lui demande de prévoir. Il sait trouver le contexte macro, la valeur comptable des entreprises, les bénéfices. Mais il ne sait pas assembler ces choses en quelque chose qui l'aide à comprendre le prix.
Avant d'enseigner quoi que ce soit à l'IA, il faut voir ce qu'elle vous cache.
Plus d'articles
J'ai Heidegger et mon carnet à côté de moi. Je me demande où tout cela nous mène, où l'intelligence artificielle nous emporte.
Soixante-dix pour cent. C'est là que commence le premier résultat de l'IA, même lorsque vous lui donnez tout le contexte de l'entreprise et les meilleurs exemples du passé. Nous parlons du type de résultat qui ne peut pas se définir de façon programmatique. Il est plus complexe. Souvent, il s'agit d'un travail créatif. Sur un type de résultat répété, j'ai atteint quatre-vingts pour cent en une semaine. Chaque point de pourcentage supplémentaire est plus difficile que le précédent.
Pendant longtemps, nous avons pris internet pour la route principale. Le lieu où se déroulent le travail et les relations. Pourtant, la plupart de ce que nous y voyons aujourd'hui est, ou sera bientôt, généré par IA : texte, images, profils et commentaires. Internet se transforme en un jeu en ligne rempli de bots, où vous ne pouvez être sûr qu'un être humain se trouve de l'autre côté de quoi que ce soit. Alors je me demande : le monde en ligne était-il la route principale, ou seulement un détour temporaire dont une partie des gens reviendra, de retour hors ligne ?
Il y a quelques jours, j'ai fait passer un entretien à un responsable marketing senior. Un homme d'expérience, des années de pratique. Je l'ai interrogé sur l'IA. Il m'a dit qu'il ne l'utilise presque pas. Il a eu une mauvaise expérience avec un résultat et a conclu qu'il était trop expérimenté pour que cela lui apporte quelque chose tant que ce n'est pas parfait. Je connais aussi l'autre versant — des professionnels qui automatisent tout ce qui peut l'être.
L'Europe n'a pas les capacités pour faire face à une guerre de drones massive et à grande échelle comme celle que nous voyons en Ukraine. Trois dépendances l'affaiblissent : la Chine fournit le matériau physique des systèmes de défense, les États-Unis fournissent les capacités que l'Europe n'a pas, et vingt-sept États ne parviennent pas à s'entendre sur le rythme, ni sur qui paie. Des plans de réarmement existent, mais ils sont mis en œuvre lentement.
Prague, 13 mai 2026. En allant au travail, je me suis mis à penser à quelque chose qui m’est resté en tête plusieurs jours. Si l’essentiel du travail routinier sur ordinateur disparaît dans les dix prochaines années, et qu’avec lui disparaît une large part du travail manuel répétitif, qu’advient-il du flux de l’argent ? Qui paie qui, et pour quoi ? Quelles couches économiques existeront, quelle sera leur taille, et quelles relations s’établiront entre elles ? Voici la carte en six couches que j’ai esquissée comme réponse.
Hier, je n'arrivais pas à m'arracher à l'ordinateur. Quand j'ai levé la tête, il était huit heures et demie du soir. J'étais resté seul à l'étage pendant environ trois heures.
L'IA va-t-elle prendre mon travail ? Un formateur certifié Google m'a dit en juin 2024 que ma profession cesserait d'exister. Vingt-deux mois plus tard, mon intitulé de poste n'a pas changé — mais quatre-vingt-dix pour cent de ce que je fais dans la journée est différent. J'ai délégué plus de ma réflexion à des agents IA que je ne l'aurais cru possible. Je n'ai pas peur. Voici pourquoi, et ce que cela signifie pour quiconque se pose la même question.
Quatre jours en Catalogne. Sans ordinateur, sans IA, presque sans réseaux sociaux. J'ai acheté ce carnet pour y noter ce à quoi je penserais et ce que je rencontrerais et apprendrais durant le voyage.